Page updated:
May 19, 2021
Author: Curtis Mobley
View PDF
The Lidar Equation
“Lidar” is an acronym for “light detection and ranging,” but should it be written as LIDAR, LiDAR, Lidar, lidar, or something else? Deering and Stoker (2014) argue that lidar has now achieved the same status as radar (radio detection and ranging) and sonar (sound navigation and ranging) and should be in lower case (except as the first word of a sentence), so that is what is used here.
The purpose of a “lidar equation” is to compute the power returned to a receiver for given transmitted laser power, optical properties of the medium through which the lidar beam passes, and target properties. There are, however, many versions of lidar equations, each of which is tailored to a particular application. For example, Measures (1992) develops lidar equations for elastic and inelastic backscattering scattering by the medium, for fluorescent targets, for topographical targets, for long-path absorption, for broad-band lasers, and so on.
The lidar equation developed here applies to the detection of a scattering layer or in-water target as seen by a narrow-beam laser imaging the ocean from an airborne platform. This equation explicitly shows the effects of atmospheric and sea-surface transmission, the water volume scattering function and beam spread function, water-column diffuse attenuation, and transmitter and receiver optics.
(Acknowledgment: I learned this derivation from Richard C. Honey, one of the pioneering geniuses of optical oceanography, and of many other fields including antenna design and laser eye surgery. Dick Honey is unfortunately little known to the general community because he spent much of his career doing classified work.)
Preliminaries
Table 1 lists for reference the variables involved with the derivation of the present form of the lidar equation.
| variable | definition | units |
| Height of the airplane above the sea surface | m | |
| Depth of the water layer being imaged | m | |
| Thickness of the water layer being imaged | m | |
| Power transmitted by the laser | W | |
| Power detected from water layer | W | |
| Transmittance by the air | nondimen | |
| Transmittance by the water surface | nondimen | |
| Receiver aperture area | ||
| Receiver field of view solid angle | sr | |
| Area at depth seen by the receiver | ||
| Solid angle of the receiver aperture as seen from depth | sr | |
| Water VSF for 180-deg backscatter | ||
| Water beam spread function | ||
| Irradiance incident (downward) onto the water layer at | ||
| Irradiance reflected (upward) by the water layer | ||
| Depth-averaged (over 0 to ) attenuation coefficient for upwelling (returning) irradiance | ||
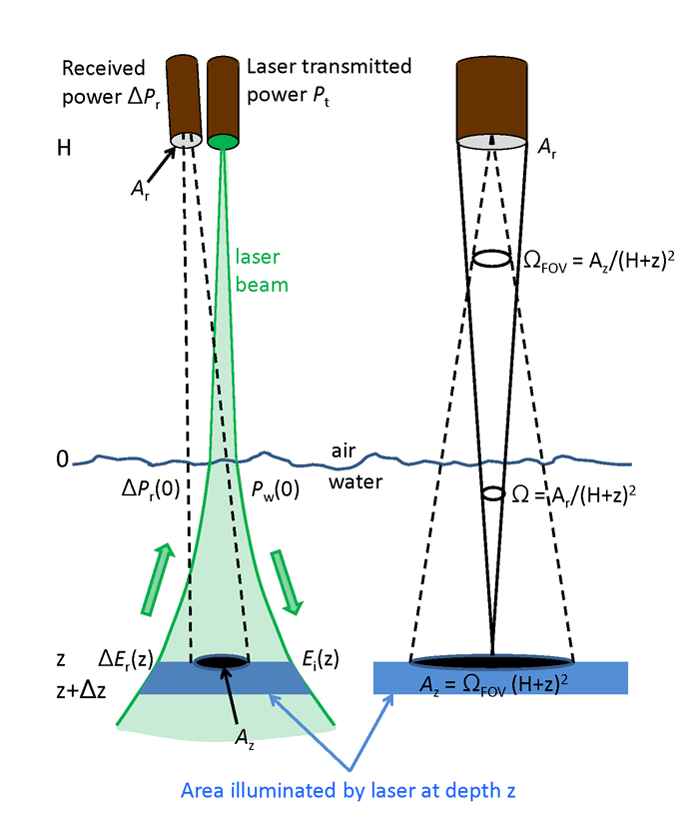
Figure 1 shows the geometry of the lidar system for detection of a scattering layer.
The volume scattering function (VSF)
Recall from Eq. (1) of the Volume Scattering Function page that the volume scattering function (VSF) is operationally defined by
where is the power incident onto an element of volume defined by a surface area and thickness , and is the power scattered through angle into solid angle . These quantities are illustrated in Fig. 2. In this derivation, quantities directly proportional to the layer thickness will be labeled with a . Thus is the power scattered by the water layer of thickness . The incident power onto area gives an incident irradiance .
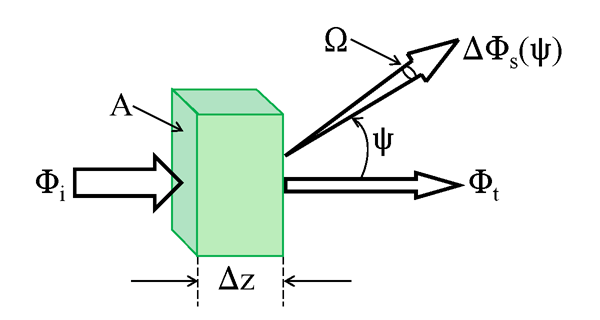
Now consider exact backscatter, which is a scattering angle of , or 180 deg. The backscattered power exits the scattering volume through the same area , so the backscattered irradiance is . The VSF for exact backscatter can then be written as
This gives
| (1) |
(Do not confuse this backscattered or reflected irradiance with , which is defined for any incident radiance distribution and for an arbitrarily thick layer of water. Here is the irradiance for a collimated incident laser beam and a thin layer of water.)
The beam spread function (BSF)
Suppose a collimated beam is emitting power in direction . Then scattering and absorption in the medium will give some irradiance on the surface of a sphere of radius at an angle of relative to the direction of the emitted beam, as illustrated by the green arrow in Fig. 3. The beam spread function (BSF) is then defined as
| (2) |
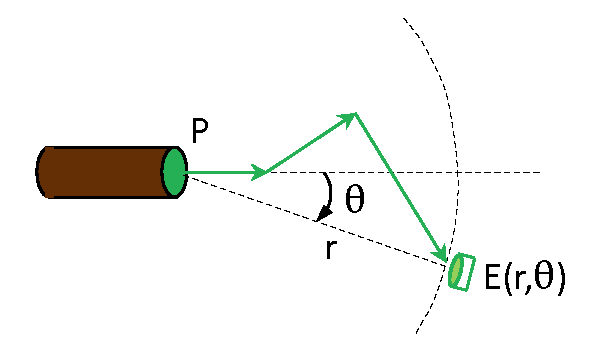
The beam spread function and its equivalent, the point spread function, are discussed in more detail on the Beam and Point Spread Functions page.
Derivation of the Lidar Equation
The derivation of the lidar equation for the stated application now proceeds via the following steps:
- 1.
- As illustrated in Fig. 1, the laser pulse has transmitted power
to start. After transmission through the atmosphere and sea surface, the
pulse has power
just below the water surface.
- 2.
- The laser pulse is still a narrow beam when it enters the water, but it then
begins to spread out because of scattering, and it is attenuated by
absorption. This process is quantified by the beam spread function. We are
interested in the “on-axis” irradiance incident onto a layer of water at depth
.
From Eq. (2), this is given by
- 3.
- The irradiance that is reflected by a layer of thickness
at
depth
is given by Eq. (1):
The solid angle is determined by the aperture size of the receiver and the distance from the receiver to the layer. This is discussed in step 7 below.
- 4.
- The irradiance heading
upward from the layer
will be attenuated by some diffuse attenuation function
as
propagates back to the sea surface:
The receiver sees only an area depth depth . It is assumed that is less than the total area illuminated by the spreading laser beam at depth . Thus we can multiply by to get the power leaving the illuminated area that is seen by the receiver. The fraction of the total power reaching the surface, which is seen by the detector, is then
is determined by the receiver field of view and the distance from the receiver to the layer.
- 5.
- The power just below the surface is now transmitted through the water
surface and through the atmosphere to the receiver. The power detected is
then
- 6.
- Combining the above results gives
- 7.
- and
can be written in terms of known parameters. We are
interested only in power that is reflected by the layer
into the
solid angle
that will take the light into the receiver. As shown
in the right panel of Fig. 1, the receiver aperture
and the range
determine
. Only power
heading into
from area ,
which is seen by the receiver, reaches the receiver.
is determined by the receiver field of view solid angle
and the
range: .
Thus the
factor in the preceding equation can be rewritten as
This equation shows how the receiver optics affects the detected power. (This is an application of the “” theorem of optical engineering. is also called the throughput or étendue of the system. Strictly speaking, the in-air solid angle decreases by a factor of upon entering the water, where is the water real index of refraction. However, the in-water increases by a factor of when entering the air. For a round trip, air to water to air, these factors cancel. They are thus ignored here and in Fig. 1.)
- 8.
- Collecting the above results gives the desired lidar equation:
(3)
Equation (3) nicely shows the effects of the transmitted power (), atmospheric and surface transmission (), receiver-optics (), water-column (), and layer thickness (). The take-home message from this equation is that in order to understand lidar data, the water inherent optical properties you need to know are the beam spread function and . This observation was in part the incentive for the work of Mertens and Replogle (1977), Voss and Chapin (1990), Voss (1991), McLean and Voss (1991), Maffione and Honey (1992), Gordon (1994b), McLean et al. (1998), Sanchez and McCormick (2002), Dolin (2013), Xu and Yue (2015), and others. These papers present several models for beam/point spread functions in terms of the water absorption and scattering properties. Several of those models are reviewed in Hou et al. (2008).
There are various arguments about what to use for , which depends on both the water optical properties and on the imaging system details. It is intuitively expected that , which is defined for a horizontally small patch of upwelling irradiance, will be greater than the diffuse attenuation coefficient for upwelling irradiance, , which is defined for a horizontally infinite light field. Likewise, we expect that will be less than , the beam attenuation coefficient. Thus . Because is an attenuation function for a finite patch of reflected irradiance, computing its value is inherently a three-dimensional radiative transfer problem. To pin down the value of more accurately thus requires either actual measurements for a particular system and water body, or three-dimensional raditative transfer simulations (usually Monte Carlo simulations) tailored to a given system and water properties.
Example calculation
To develop some intuition about Eq. (3), consider the following example application. Suppose a 532 nm laser is being used to look for objects in the water that have an area of . The receiver FOV must be small enough that the object can be distinguished from its surroundings. For and , this requires that
For a 15 cm radius receiving telescope, . For normal incidence at the sea surface, , and for a clear atmosphere, . Suppose the water is Jerlov type 1 coastal water for which (Light and Water, page 130), and assume that . Further assume that , since the lidar beam attenuation will be more “beam like” than diffuse attenuation, and . Finally, take (Light and Water, Table 3.10 for “coastal ocean” water). Then for at a depth of 10 m, the water returns the fraction
of the transmitted power.
Now suppose that the laser beam hits an object at = 10 m whose surface is a Lambertian reflector of 2% (irradiance) reflectance. Then 0.02 of is reflected into . The layer backscatter is then replaced by
If all other terms remain the same, the object would return about three times the signal as the water itself.
 See comments posted for this page and leave your own.
See comments posted for this page and leave your own.